引言
大数据计算和普通的程序并无本质区别:数据输入=>计算=>输出和结果的持久化。这里的挑战在于计算的效率和容错性。由于数据输入巨大,计算的效率是基本的要求。为了在通用硬件上高效完成大量计算,唯一的途径就是将计算任务拆分分布式计算。这就引出了新的问题:分布式计算资源的管理(Mesos,YARN),分布式计算失败后的恢复(容错性)(Spark RDD),以及分布式的数据输入和保存(分布式文件 HDFS).hadoop 生态圈就是为了解决几个问题设计的 (YARN,MapR,HDFS).只不过在计算这一环节 Spark 做的更加高效取代了 MapR.所以先看下 hadoop 的核心两个组件。
HDFS
- HDFS 是 hadoop 的虚拟分布式文件系统。满足大数据问题下要求的:可扩展的,容错的,硬件通用的和高并发的特性.HDFS 最重要的特性是不可变性–数据提交到 HDFS 后即不可更新了,也就是所谓的 WORM(write once read many).
- 文件在 HDFS 中是以 block 构成,默认一个 block 是 128M.block 是是分布式的,即如果集群中如果有多于 1 个节点,那么有文件可能会被分布在多个节点上.block 是被复制的,这主要是两个目的:1.容错,2.增加数据局部性的概率,有利于访问.block 复制在数据节点接收(ingest:消化)block 时同时发生。如图所示:
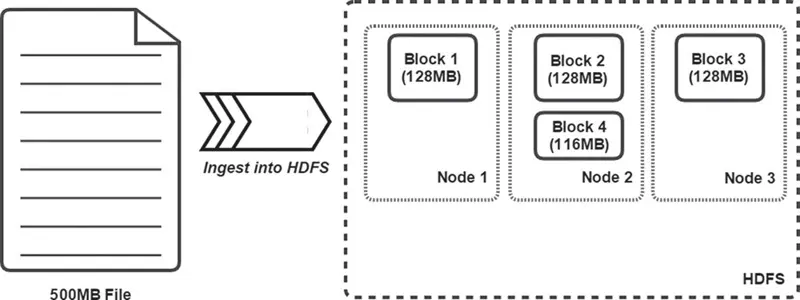
- NameNode:不知道怎么翻译,NameNode 主要负责管理 HDFS 的元数据,包括 directory,文件对象和相关属性(e.g. ACL),元数据是常驻内存中的,硬盘上也有备份以及日志保证持久性和崩溃后的一致性(和数据库相似).还包括 block 的位置信息–block 之间的关系。注意,数据(文件)并不经过 NameNode,否则很容易成为性能瓶颈,数据是直接到达 DataNode,并上报给 NameNode 管理。
- 数据节点(DataNode)负责:block 复制;管理本节点的存储;向 NameNode 上报 block 信息。注意,数据节点不会意识到 HDFS 的目录(directory)和文件(Files)的概念,这些信息是 NameNode 管理保存的,客户端只会和 NameNode 交道。
- hdfs 客户端分为:fs shell;hdfs java api;rest proxy 接口(HttpFS 等).
- 常见命令:
# 上传一个文件 -f表示覆盖
hadoop fs -put -f jour.txt /user/dahu/jour/
# 下载
hadoop fs -get /user/dahu/jour/jour.txt
# ls
hadoop fs -ls /user/dahu/
# 删除 -r表示递归,删除目录
hadoop fs -rm /user/dahu/jour/jour.txt
hadoop fs -rm -r /user/dahu/jour
YARN
- YARN:Yet Another Resource Negotiator 是 hadoop 的资源管理器.YARN 有个守护进程–ResourceManager,负责全局的资源管理和任务调度,把整个集群当作计算资源池,只关注分配,不管应用,且不负责容错.YARN 将 application(或者叫 job)分发给各个 NodeManager,NodeManager 是实际的 worker 或者 worker 的代理.ResourceManager 主要有两个组件:Scheduler 和 ApplicationsManager. 下图是 YARN 的结构示意图:
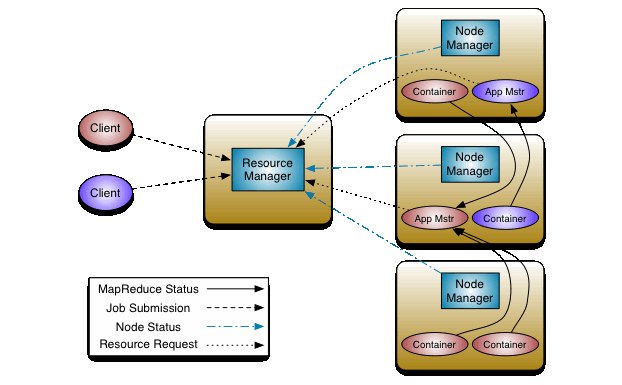
上图中 ResourceManager 负责管理和分配全局的计算资源。而 NodeManager 看着更复杂一些:1.用户提交一个 app 给 RM(ResourceManager);2.RM 在资源充足的 NodeManager 上启动一个 ApplicationMaster(也就是这个 app 对应的第一个 container).3.ApplicationMaster 负责在所有 NodeManagers 中协调创建几个 task container,也包括 ApplicationMaster 自己所在的 NodeManager(上图中紫色 2 个和红色的 4 个分别表示 2 个 app 的 task container 和 ApplicationMaster).4. NodeManager 向各个 ApplicationMaster 汇报 task container 的进展和状态.5. ApplicationMaster 向 RM 汇报应用的进展和状态.6.RM 向用户返回 app 的进度,状态,结果。用户一般可通过 Web UI 查看这些。
上面的示意图是 YARN 的核心概念,Spark 程序的运行结构示意图和上面的示意图相同。每个组件都可以近似一样的理解,例如,上面的 Client 在 Spark 中叫 Driver 程序;ResourceManager 在 Spark 中叫 Cluster Manager(为了理解方便,认为一样即可,Spark 的 ClusterManager 目前主要有 YARN,Mesos 和 Spark 自带的三种);NodeManager 就是 Spark 中的 Worker Node.
Spark 基本概念
- 上图中的 client 程序在 Spark 中即 Driver 程序.Driver 就是我们编写 Spark 程序 app 的主要部分,包括
SparkContext的创建和关闭以及计算任务(Task)的计划(Planning,包括数据数据,转换,输出,持久化等).SparkContext负责和 Cluster Manager 通信,进行资源申请,任务的分配和监控。一般认为SparkContext代表 Driver. - ClusterManager:就是上面说的三种-Standalone,YARN,Mesos.
- WorkerNode: 集群中运行 app 代码的节点,也就是上图中 YARN 的 NodeManager 节点。一个节点运行一个/多个 executor.
- Executor:app 运行在 worker 节点的一个进程,进程负责执行 task 的 planning.Spark On YARN 中这个进程叫 CoarseGrainedExecutorBackend.每个进程能并行执行的 task 数量取决于分配给它的 CPU 个数了。下图是一个 Spark 程序集群概览图,和上图很相似。
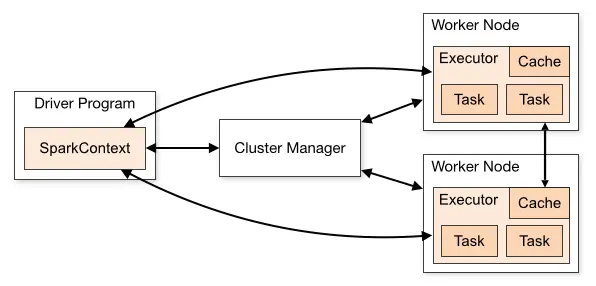
- 仔细对比上面两个示意图,在 YARN 的结构示意图中,ResourceManager 为程序在某个 NodeManager 上创建的第一个 container 叫 ApplicationMaster,ApplicationMaster 负责只是其他的 task container.在 Spark On YARN 有两种运行模式:client 和 cluster 模式。在 cluster 模式下,用户编写的 driver 程序运行在 YARN 的 ApplicationMaster 的内部。
*RDD:Spark 的核心数据结构。后面详细介绍,可以简单的理解为一个 Spark 程序所有需要处理的数据在 Spark 中被抽象成一个 RDD,数据需要被拆分分发到各个 worker 去计算,所以 RDD 有一个分区(Partation)概念。一般我们的数据是放在分布式文件系统上的 (e.g. HDFS),可以简单理解为一个 RDD 包含一或多个 Partation,每个 Partation 对应的就是 HDFS 的一个 block.当然,Partation 不是和 HDFS 的 block 绑定的,你也可以手动的对数据进行分区,即使他们只是待处理的一个本地文件或者一个小数组。一个 Partation 包含一到多个 Record,Record 可以理解为文本中的一行,excel 的一条记录或者是 kafka 的一条消息。 - Task:RDD 的一个 Patation 对应一个 Task,Task 是单个分区上最小的处理单元。
RDD
pass
SparkStreaming
pass
SparkStreaming+Kafka
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092,anotherhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topicA", "topicB")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(record => (record.key, record.value))
DStream 的 elements:record is ConsumerRecord<K,V>: A key/value pair to be received from Kafka. This consists of a topic name and a partition number, from which the record is being received and an offset that points to the record in a Kafka partition.包含 key(),offset(),partation() 方法等。
- 当一个 StreamingContext 中有多个 input stream 时,记得保证给程序分配了足够的资源(特别是 core 的数量,必须大于输入源的数量).
- 本地执行程序时,不要使用“local”or“local[1]”as the master URL,streaming 程序至少需要两个 thread,一个接受数据,一个处理数据。直接使用 local[n],n>输入源个数。
- DStream 和 RDD 一样支持各种 trans 和 action
- DStream is batches of RDDs.
常见错误
数据库 (mysql redis) 连接的可序列化问题
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}
// 上面的写法会导致 connection 不可序列化的错误:Task not serializable
// RDD 的函数 (map,foreach) 会被序列化发送到 worker 节点执行,但是 connection 是和 tcp 连接,和机器绑定的,无法序列化
dstream.foreachRDD { rdd =>
rdd.foreach { record => // on worker node
val connection = createNewConnection() // 给每个 record 处理时新建一个连接,会导致严重的数据库连接性能问题
connection.send(record)
connection.close()
}
}
// 更好的方式是给每个 partation 新建一个连接
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
// 最好的方法是维护一个静态线程池:
[ConnectionPool](https://github.com/RedisLabs/spark-redis/blob/master/src/main/scala/com/redislabs/provider/redis/ConnectionPool.scala)
// then use in partition
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
// Note that the connections in the pool should be lazily created on demand and timed out if not used for a while.
// This achieves the most efficient sending of data to external systems.
// 示例
case class RedisCluster(clusterHosts: String, password: String) extends Serializable {
def this(conf: SparkConf) {
this(
conf.get("spark.redis.host", Protocol.DEFAULT_HOST),
conf.get("spark.redis.auth", null)
)
}
/**
*
* @return use for JedisCluster or JedisPool
*/
def toSet(): java.util.Set[HostAndPort] = {
val nodes: mutable.Set[HostAndPort] = mutable.Set()
for (host_port <- clusterHosts.split(",")) {
val hp = host_port
print(hp)
nodes += HostAndPort.from(host_port)
}
nodes.asJava
}
}
object RedisClusterUtils extends Serializable {
@transient private lazy val pools: ConcurrentHashMap[RedisCluster, JedisCluster] =
new ConcurrentHashMap[RedisCluster, JedisCluster]()
/**
* 获取一个 JedisCluster
* @param rc
* @return
*/
def connect(rc: RedisCluster): JedisCluster = {
pools.getOrElseUpdate(rc, {
val poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(250)
poolConfig.setMaxIdle(32)
poolConfig.setTestOnBorrow(false)
poolConfig.setTestOnReturn(false)
poolConfig.setTestWhileIdle(false)
poolConfig.setNumTestsPerEvictionRun(-1)
val jedisCluster = new JedisCluster(rc.toSet(),
3000,
3000,
5,
rc.password,
poolConfig)
jedisCluster
})
}
/**
* 查询币种对应汇率
* @param jedisCluster 目标 redis
* @param ccyCd 币种代码
* @return 折美元汇率
*/
def getCcyRatio(jedisCluster: JedisCluster, ccyCd:String): Double ={
val res = jedisCluster.get("CCY:"+ccyCd)
res.split(":")(2).toDouble
}
}
参考
Design Patterns for using foreachRDD
Redis on Spark:Task not serializable
How to create connection(s) to a Datasource in Spark Streaming for Lookups
- DStream 的 RDD 分区数是由 topic 分区数相同的。